GeneFace复现
简单记录了下跑GeneFace代码的流程还有自己踩的一些坑
环境配置
依照环境配置文档逐步进行环境配置
CUDA和安装Python库
去autoDL租了块3090,然后按文档配置CUDA和Python库
直接依照指示就行
中途遇到问题
使用sudo apt update更新本地缓存
晚上回来后
AutoDL帮助文档
按帮助文档指引通过wsl打开ubuntu ssh连接后执行jupyter-lab
发现问题
重新下载 pip install jupyterlab
问题解决
2023-09-03 11:36:32
pip install -r docs/prepare_env/requirements.txt 出错
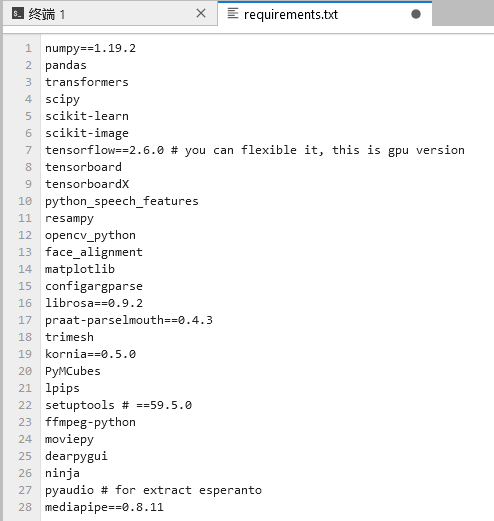
修改numpy版本解决冲突
还是报错
发现numpy版本应该是~=
再次修改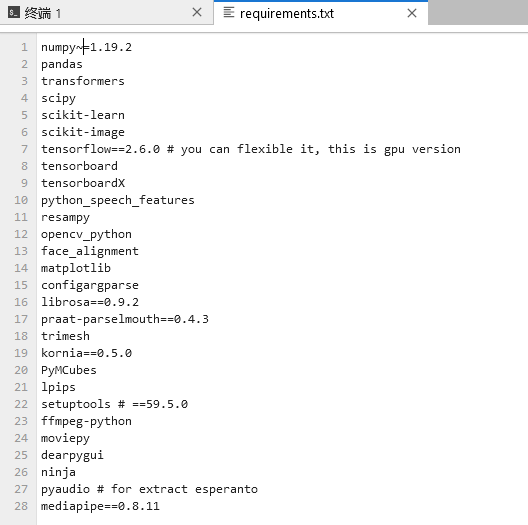
准备3DMM模型
下载3DMM model(需要申请)
剩下的文件直接下载,通过阿里云盘传到autoDL
然后按照指示移动到指定文件夹
mv文件遇到问题
mkdir -p创建文件夹就行
解压 BaselFaceModel.tgz
哈哈哈哈每次都要查阅命令
tar -xzf ./deep_3drecon/BFM/BaselFaceModel.tgz
使用命令解压
加个v以便看清流程
解压后不在文件夹内
发现解压到了目前终端所在的目录,手动移动过去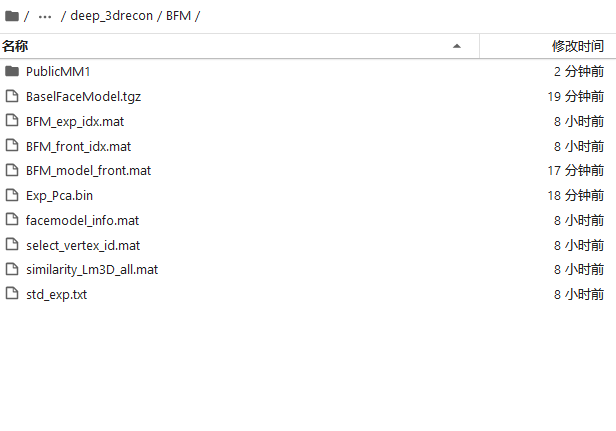
使用python convert_BFM.py生成face_tracking需要的文件
报错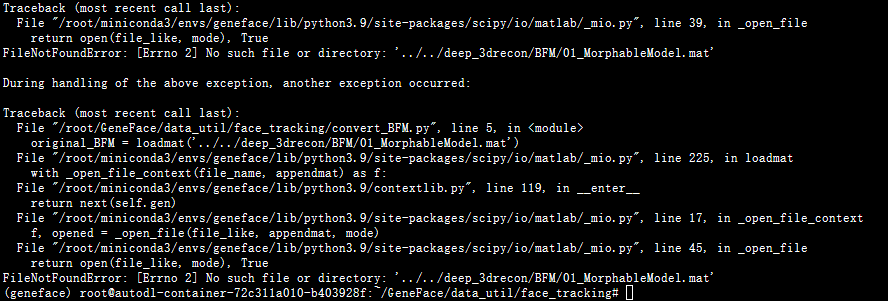
把PublicMM1文件夹中的01_MorphableModel.mat拿出来,路径不对
之后成功
验证安装成功
还是按环境配置文档的指示
跑通 deep_3drecon_pytorch 项目的原始example
CUDA_VISIBLE_DEVICES=0 python deep_3drecon/test.py
时报错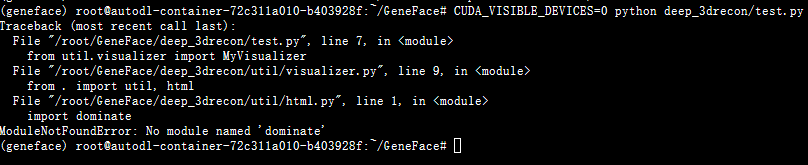
直接pip install dominate完事
example成功跑通!!!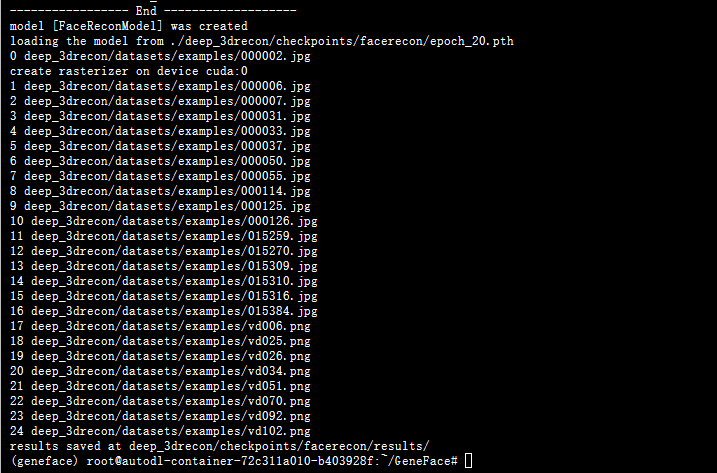
后面验证与GeneFace的桥梁?
哈哈哈哈没懂文档在说啥,照做了直接反正
哈哈哈哈还是先看看实验的Results吧
只有epoch的文件后续应该要渲染吧,不管了,环境配好了继续看readme先
依照README跑通模型 准备数据
readme 文档
好吧文档里面让遵循docs/prepare_env、docs/process_data 、docs/train_models几个文档的步骤,搞忘了哈哈哈哈
这节应该叫准备数据哈哈哈哈
开始
一个文档是处理LRS3-TED数据集,一个文档是教你处理自己的目标人的video
先处理LRS3-TED吧
文档说数据集太大了处理太耗资源提供了处理好的,直接用吧
这处理好的27个G也还是太大了哈哈哈哈
挂着下载然后睡觉去吧 2023-09-04 01:36:06
下好了明天直接train,感觉数据集蛮大明天可以多租几张卡哈哈哈哈
2023-09-04 15:46:10
先复现定性实验吧,照着文章附录中的超参数来。
但是要84个小时要不要多租张卡哈哈哈
使用cat lrs3.zippart* > lrs3.zip将下载的处理好的zip子文件还原成压缩包
然后unzip lrs3.zip
记得移动到 data/binary/lrs3 目录下
哈哈哈系统盘好像大小不够了,把工程copy到数据盘一份吧
训练模型
readme 文档
把预训练的模型下载一波然后放到指定文件夹
然后根据readme文件开始训练
记得处理目标人的MP4视频
处理May视频一直卡着,而且报错AttributeError: _2D
问题和issue中的
https://github.com/yerfor/GeneFace/issues/149一样
改了之后2D的报错消失,但是还有报错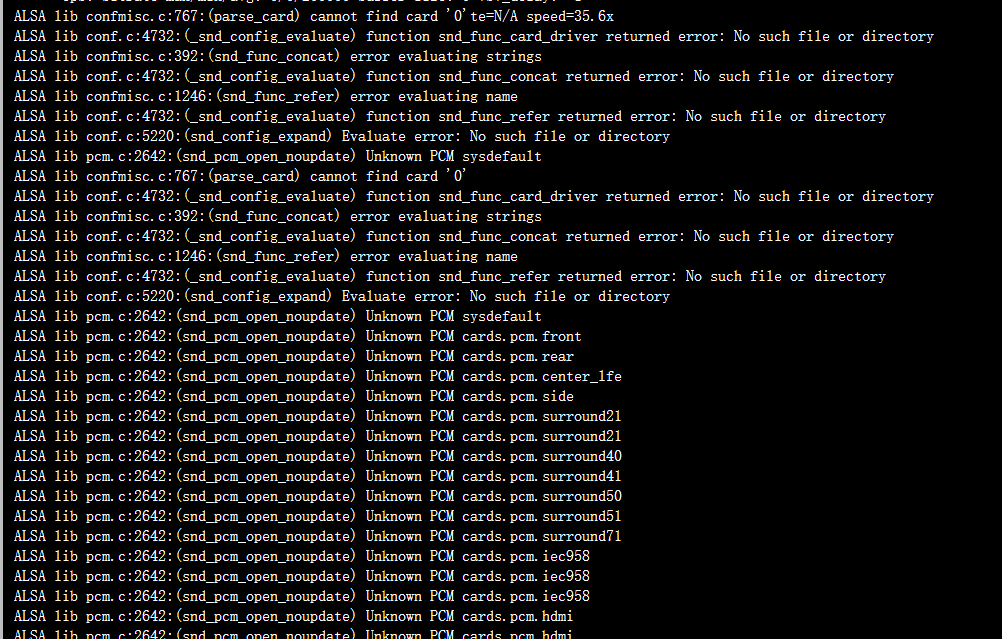
可以往下运行,但是运行到后面就卡着了
推测是声卡问题
aplay-l发现没有声卡
但是代码好像不需要用到声卡,上面的报错干脆不管吧
慢慢等
但是中途又出错了,一直等到最后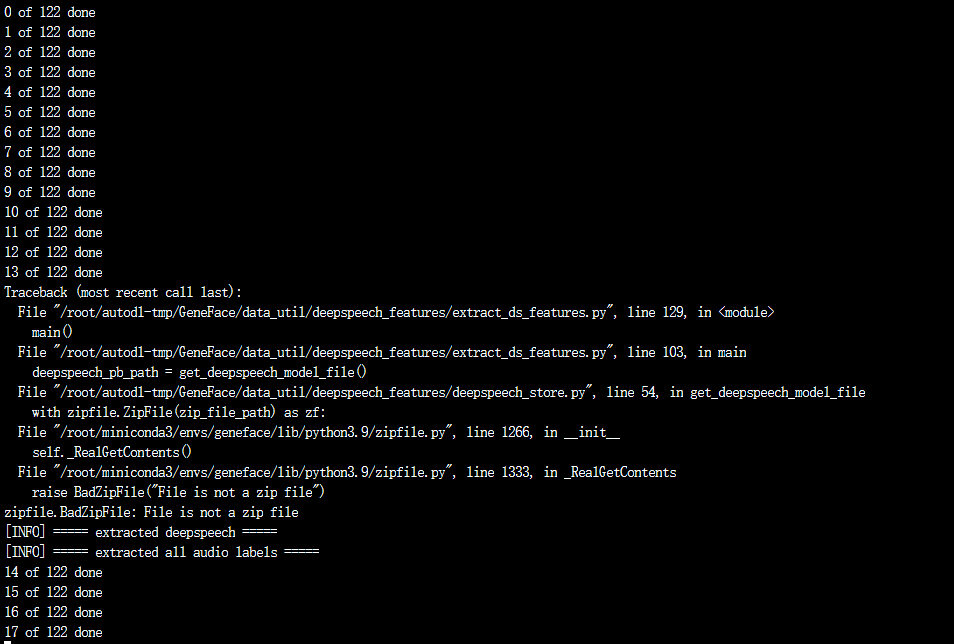
最后又出现AttributeError: _2D还有FileNotFoundError: [Errno 2] No such file or directory: ‘data/processed/videos/May/aud_deepspeech.npy’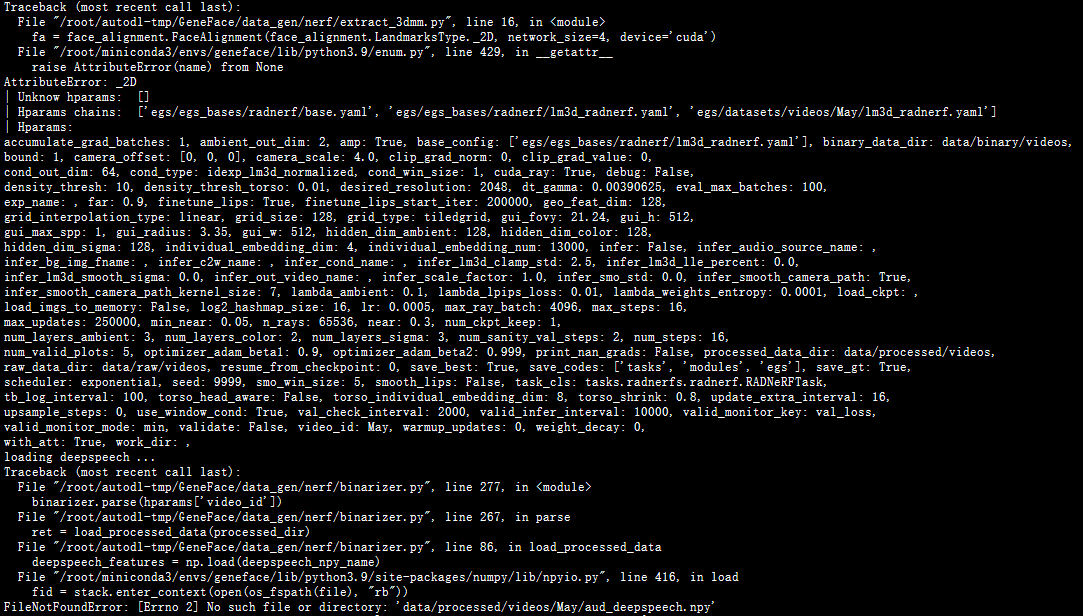
第一个问题按上个issue里面提的修改指定文档就行
第二个问题应该是deepspeech下载失败
https://github.com/yerfor/GeneFace/issues/150
根据issue里面处理试试!!!
重新试了一下按但还是卡着,应该是代理的问题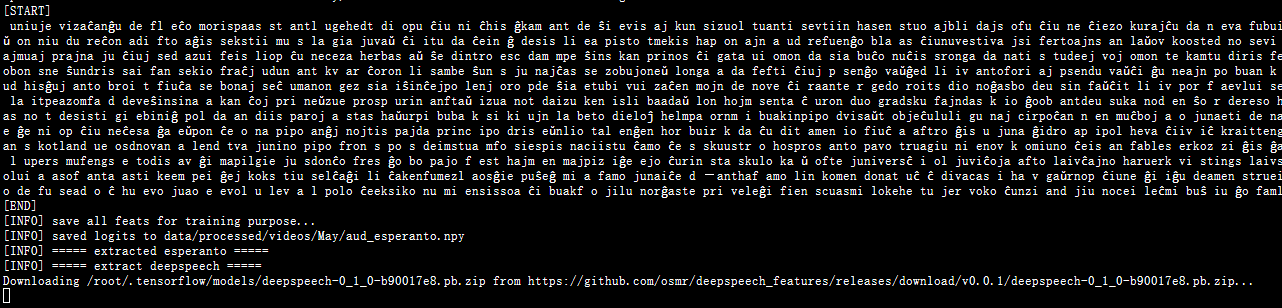
干脆自己本地到指定的地址https://github.com/osmr/deepspeech_features/releases/download/v0.0.1/deepspeech-0_1_0-b90017e8.pb.zip下载了传到服务器上,然后移动到
/root/.tensorflow/models/deepspeech-0_1_0-b90017e8.pb.zip
上述修改后继续运行
还是卡住,应该是自己.zip文件移动过去没手动解压的缘故
重开一个终端及解压
然后按150 issue的处理方法处理
直接跑通了
autoDL自带的代理太辣鸡了,下次还是自己配置代理吧
2023-09-05 02:12:14
挂着等May视频处理完毕吧,先睡觉先,然后明天继续弄
2023-09-05 10:30:49
我去,睡过头了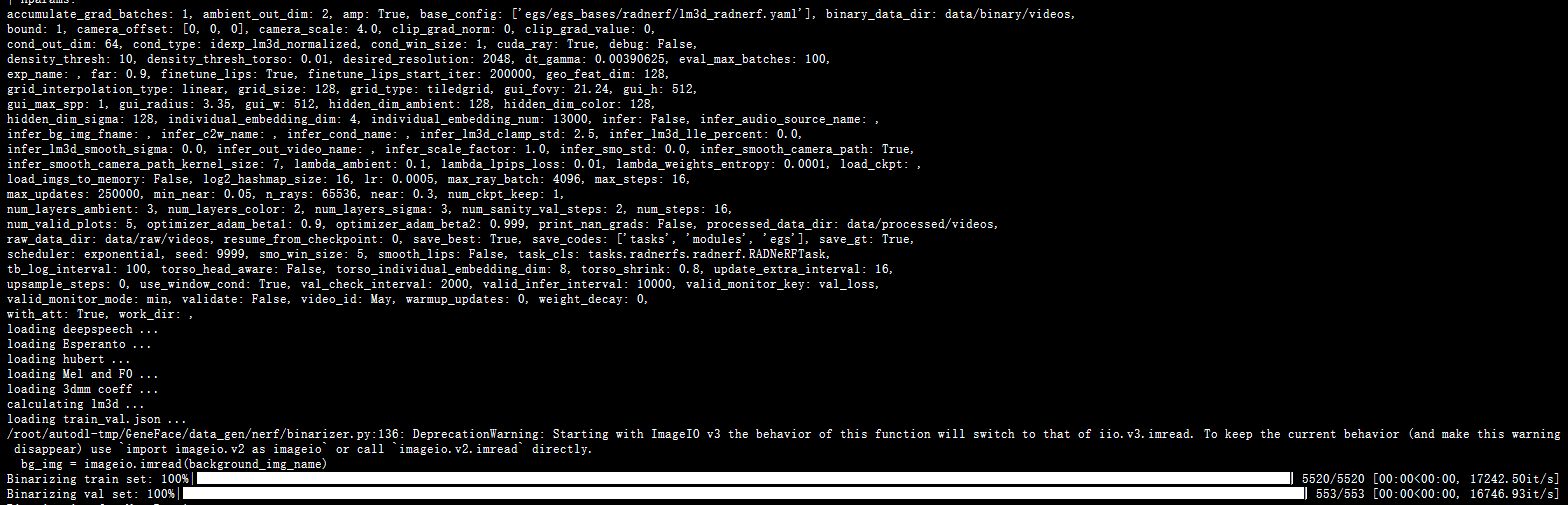
视频处理好了
跑一跑预训练的模型吧先
进展很顺利
执行NeRF的脚本又遇到龟速下载了
还是自己本地下载了上传吧
运行很顺利
从服务器上下载下来
 微信
微信 支付宝
支付宝


