论文阅读:GENEFACE GENERALIZED AND HIGH-FIDELITY AUDIO-DRIVEN 3D TALKING FACE SYNTHESIS
这两天读了GeneFace的论文并且跑了下代码,简短地记了些东西
Abstract
任务: Generating photo-realistic video portrait with arbitrary speech audio
talking face generation
下图是官方演示页面中用唱歌声生成人脸的demo的动图
(复现的时候读文档发现这个歌曲是DiffSinger生成的,没玩过这个模型后面可以玩玩~)
贡献:提出了Gene-Face,一种基于NeRF的模型
首先在唇语语料上训练variaitional motion generator,使用post-net标定结果
此外提出一种head-aware torso-NeRF来渲染预测到的面部运动
上个GeneFace的结构图吧,还是看图直观捏,简而言之模型分为三部分
Introduction
之前一直使用GAN做渲染器,但是因为GAN的各种蛋疼问题(难train和模式坍塌你懂的)
目前流行用NeRF做
最近的端到端的框架面临两个问题
- weak generalizability due to the small scale of training data
训练数据过小导致模型鲁棒性和OOD的能力不够强 - mean face problem
因为音频到脸是一对多的映射所以学习到的脸会过度平滑和模糊(个人理解相当于学习得到的结果是一个稍大的范围,不是一个点)对于一些过于复杂的音频会出现半开和模糊的嘴的问题,导致图像质量不高和唇部同步不好
paper中提出的GeneFace就是用来解决这两大问题的
解决方法
对于问题一,paper中提出了audio-to-motion model的模型,就是整个框架的第一部分~
然后利用大规模唇语数据集中的audio-motion pairs成对的数据来训练模型
对于问题二,paper运用variational autoencoder (VAE) with a flow-based prior作为audio-to-motion model的结构,而不是使用基于线性的模型
这样我们就得到了准确富有表达的面部运动
思考
==为什么引入非线性的模型能够解决这个问题呢?==
2023-09-04 01:08:47
个人感觉应该是VAE引入非线性因素增强了模型的表达能力吧
好像不太对哈哈哈哈,先留着这个问题后面思考思考吧
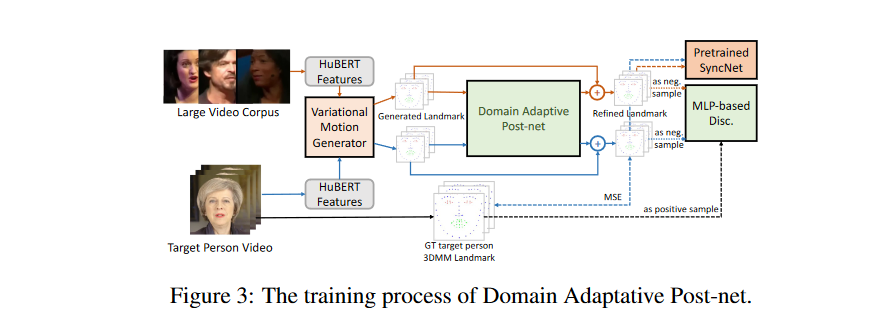
此外,因为
due to the domain shift between the generated landmarks (in the multi-speaker domain) and the training set of NeRF (in the target person domain)
两个训练好的模型(G和NeRF的渲染器之间有域偏移)
渲染出的帧不够逼真
思考
我能理解域偏移 但是paper为什么能很好想到呢?
2023-09-04 01:14:01
初步感觉是作者们试了很多方法改进,最后发现是域偏移哈哈哈哈 或者是个问题做多了有直觉
所以因为这个问题作者们设计了框架中的第二部分来做domain adaptation来rig the predicted landmarks into the target person’s distribution
让两个分布接近
文章自己也总结
To summarize, our system consists of three stages
1 Audio-to-motion. We present a variational motion generator to generate accurate and expressive facial landmark given the input audio.2 Motion domain adaptation. To overcome the domain shift, we propose a semi-supervised adversarial training pipeline to train a domain adaptative post-net, which refines the predicted 3D landmark from the multi-speaker domain into the target person domain.
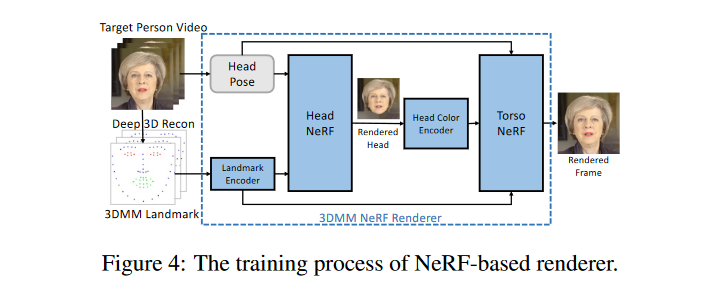
3 Motion-to-image. We design a NeRF-based renderer to render high-fidelity frames conditioned on the predicted 3D landmark.
模型有这三部分
文章三大贡献
总结一下就是提出了GeneFace这个牛逼模型
然后是第一个分析mean face问题的工作
还有就是这个模型跟其他基于NeRF和GAN的baseline比起来比较先进
RELATED WORK
2023-09-04 01:23:51
先随便看看,才第一次接触这个任务,后面有得是时间读更多的paper~
2023-09-04 13:34:13
以前的工作有两方面
- Audio-driven Talking Head Generation
一开始的工作只是从静止的面部图像合成嘴唇的运动
,后面有人做合成整个头。但是这些方法由于缺乏3D建模用来做姿态控制不太可行。然后许多工作开始探索从单目视频中提取3D Morphable Model (3DMM)来表示面部运动
公式如下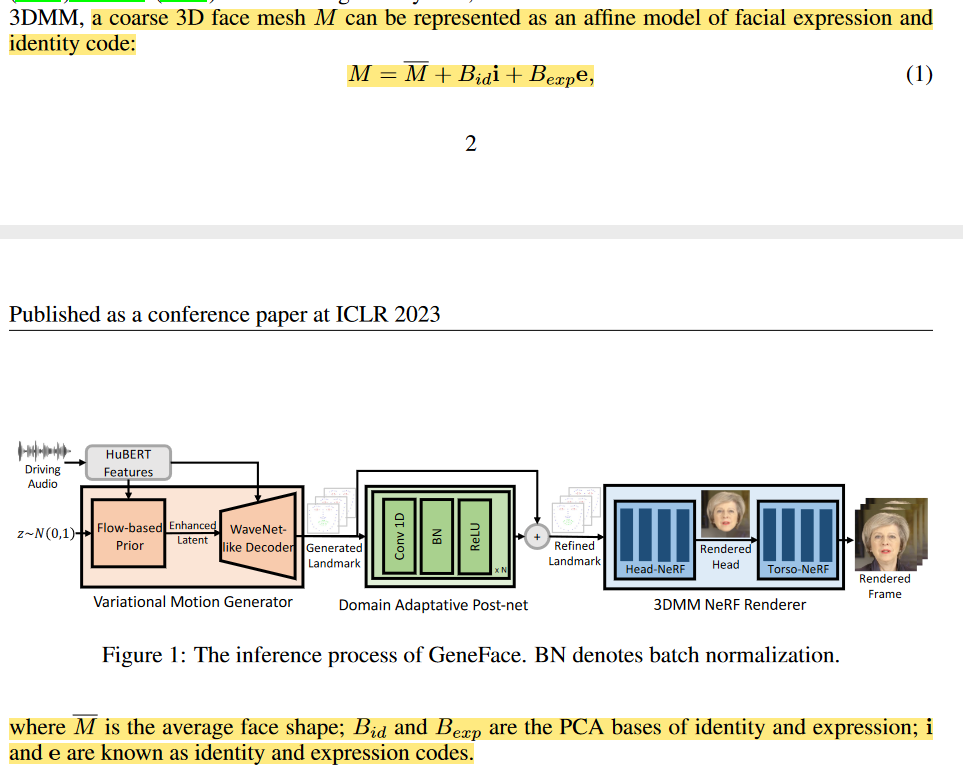
M等于平均的面部MESH在上面加上identity和expression的影响
但是由于3DMM只能定义一个粗糙的头部的3D mesh,像皱纹,头发,牙齿等细节被忽略掉了。用基于GAN的方法得到逼真的结果充满挑战。使用基于NeRF的方法渲染我们不需要改善3DMM模型还有添加额外条件,可以把细节留给NeRF的隐空间建模。
Encoding Decoding 这个过程中细节可以由隐空间还原
思考为什么?
- Neural Radiance Field for Rendering Face
在人像渲染领域最近NeRF很火因为可以渲染得到富有细节的高保真图像
但是之前基于NeRF的工作都只关注得到质量更好的图像和减少训练开销,没有考虑到out of domain音频的泛化性问题。
GeneFace工作又用了基于NeRF的渲染器得到高保真的图像,又引入audio-to-motion model解决out of domain 音频的泛化性问题。
GENEFACE
详细了解下模型
不过感觉可以慢慢看边看边把模型跑通,然后复现文章的实验
2023-09-04 01:29:00
哈哈哈还是直接先看看实验部分吧
实验部分用的LRS3-TED数据集,先跑一下看看大致结果对不对,看看效果然后详细了解模型的结构~
三部分详细结构如下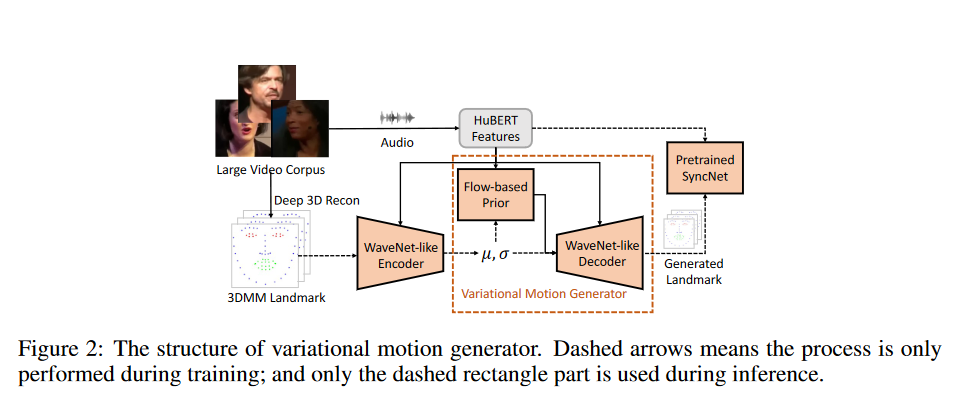
EXPERIMENTS
数据集准备
LRS3-TED数据集用来训练Generator和post-net。
一段带音轨的特定的人的讲话视频用来渲染NeRF渲染器
数据处理
说了下音频和video各自的处理方法
用了先前的几个著名工作当baseline
For variational generator and post-net, it takes about 40k and 12k steps to converge (about 12 hours). For the NeRF-based renderer, we train each model for 800k iterations (400k for head and 400k for the torso, respectively), which takes about 72 hours.
我发现文中说的训练时间好长哈哈哈哈
定量评估
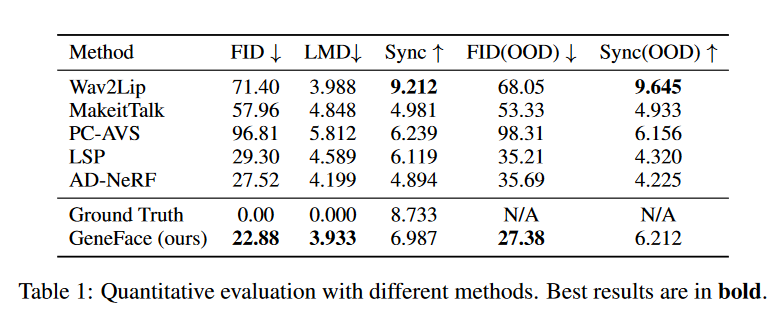
三个指标 OOD是指使用了OOD的音频,比如跨语言,跨性别,唱歌等等
实验结果表明GeneFace比其他都好
Wav2Lip是用SyncNet联合训练的所以Sync比ground truth还高
视觉效果对比
Since we use 3D landmarks as the condition of the NeRF renderer, it address the mean face problem and leads to better lip syncronization and visual quality than AD-NeRF.
定性评估
消融实验
做了消融实验验证每一部分的必要性
 微信
微信 支付宝
支付宝


